
Data Overload
The current approach to observability, in the form of logging, traces, and metrics, has accelerated data growth within enterprises. This is unlike the previous data volumes stored in databases, data warehouses, and data lakes for business intelligence reporting. No, it is far more significant because it is related to events recorded at the microscopic computational level. What was previously a simple entry representing a customer order has now become hundreds, if not tens of thousands, of composite data points and contextual payloads, further compounded by the call fanout in the backend as one service calls many others, and they, in turn, call other services.
Nearly all the observability data collected today lacks any apparent affinity with actionable insight into the behavior and controllability of a complex network of services. It is probably safe to say that this data has negligible value, operationally speaking, other than acting as a searchable forensic dataset. However, the cost of such data continues to grow immensely as retention periods are elongated out of fear that a search might be needed one day. This is not just unsustainable; it is wasteful when most site reliability engineers only skim the data lake’s surface and scan the charts of an even smaller scope. We must reshape our thinking if we are to avoid a collapse.
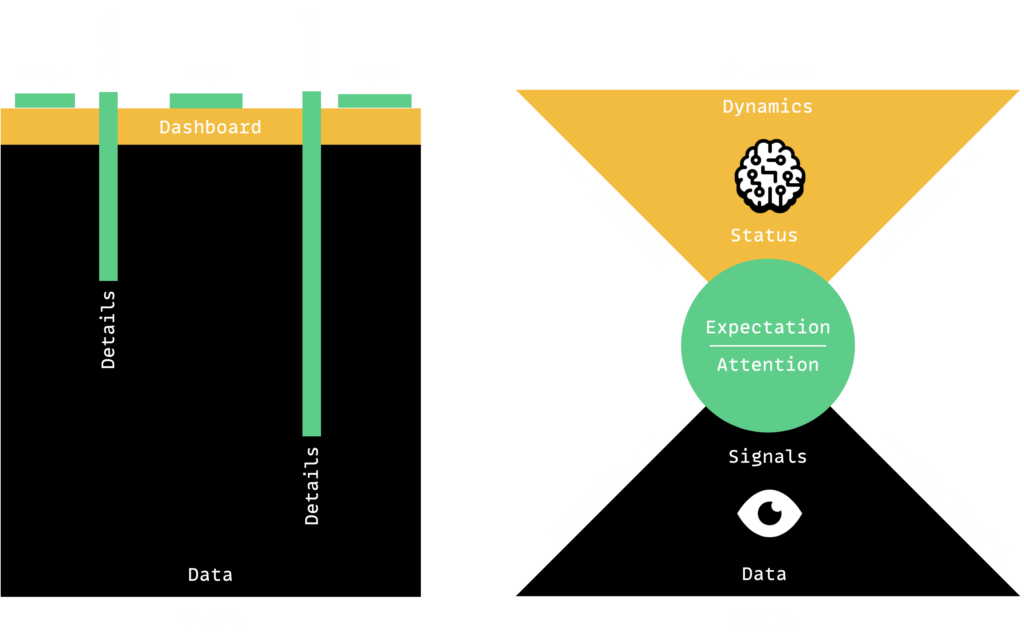
Double Cone Model
We can and must do better by taking inspiration from how cognitive scientists of the past have conceptualized the processing of sensory stimuli by a human brain into an informational mental model of the world that is relevant and salient to survival and the fulfillment of goals and drives. The Double Cone Model, shown above with some extensions and elaborations, is a useful conceptualization.
The bottom cone represents the sensory input, where instruments turn interaction and event occurrences into qualitative measurements, such as signals, reducing data volumes and surfacing only what is significant up through layers within the cone until reaching the center. It is important to note that signals can be converted and consolidated into higher-order signals moving from concrete to more abstract.
In the center, two major cognitive computational processes continuously adapt to inputs (from above) and outputs (from below) – attention and expectation. Both of these processes are coupled in that expectations, typically defined by plans and priors, prime the attention process on where and what to give focus selectively and, in doing so, allocate resources from a limited capacity reserve. The attention process can be aroused with novelty in signaling and inhibited by habituation. Across both processes, patterns, and predictions are formed and evaluated. Higher forms of information, such as dynamics and stability, are created and fed upwards.
In the top cone, which is inverted, the output from attention and expectation processes, such as deviations, become input sources for information-synthesizing and sense-making processes that extract and represent the dynamics of the environment in terms of states, sequences, scenes, settings, situations, scenarios, and scripts. Here the information model is much closer to how the human mind reasons about the physical and social world, with narratives (re)constructed and trajectories simulated sourced from plans, priors, and projections.