This article was first published in 2012.
Abstract
This post delves into the underlying reasoning, thought processes, and concepts that underpin the technology we refer to as Signals. We firmly believe that Signals holds the potential to revolutionize the design and development of software, the performance engineering of systems, and the management of distributed interconnected applications and services.
We initially designed Signals to analyze the sub-microsecond execution performance variations of software in extremely low-latency, high-frequency transaction and messaging environments. Later, our design evolved to support the development of software components and libraries with self-adaptive capabilities.
Human Signals
Today, when we’re assigned a job to perform, we initiate an exchange to define and set the job parameters and constraints. This exchange drives the planning of the work items required to complete the task. Finally, there’s an exchange where the product is handed over. Around the same time these exchanges occur, both parties implicitly and explicitly communicate signals that can be crucial in executing the planned work items. These signals can explain deviations from expected performance and guide changes and adaptations in future job assignments and planning.
Here are examples of explicit signals communicated on completion of a task beyond its expected time:
- “Some parts were not in stock, so we had to create them as we went along.”
- “We had problems sourcing the material from the suppliers you gave us.”
- “We underestimated the work effort involved, which we had largely based on your past orders.”
- ”We have completed the job but did incur some additional charges, which we are passing on to you.”
- “We had some capacity management issues which we could not have foreseen when we took the job.”
- “We did not make the job run window and then had to contend with other jobs of higher priority.”
Signals can also occur during the submission and acceptance of a job.
- “I’m in a hurry and would appreciate it if this could be done as soon as possible.”
- “The last time we experienced a delay. I expect you to prioritize to compensate.”
- “We are using the same materials as before, which caused some complications, but hopefully, we’ve learned.”
- “You are new around here. Have you looked at our file and past orders and planned accordingly?”
Software Signals
Most APIs we design and use today don’t allow exchanges, signal communication, or observation. They don’t even permit signals to be propagated, profiled, or persisted. Even when stateful, APIs are usually stateless, like bindings between callers and callees, users and sessions, services and resources, and so on. The state maintained across exchanges for these bindings is rarely related to the signals themselves but rather to the arguments and return values. Since we have limited memory of past behavior, except for state-side effects, we can’t achieve the significant performance and quality improvements we expect in real-world associations and their interactions. Therefore, software needs to become more adaptable, and signals can play a crucial role in driving this adaptation.
A signal has a namespace identifier, much like a package or class. It also has a path consisting of a sequence of boundary names, which reflects its origin and propagation upwards through boundaries.
For each signal within a named boundary scope, the occurrence and strength of signals are tracked and accumulated within the property values count and total. The count is incremented by one every time a signal is emitted. When code emits a signal, it can optionally pass an optional numeric argument, which we refer to as the strength, for each signal. Each signal has its arbitrary scale. The strength is added to the total for the corresponding signal within the boundary.
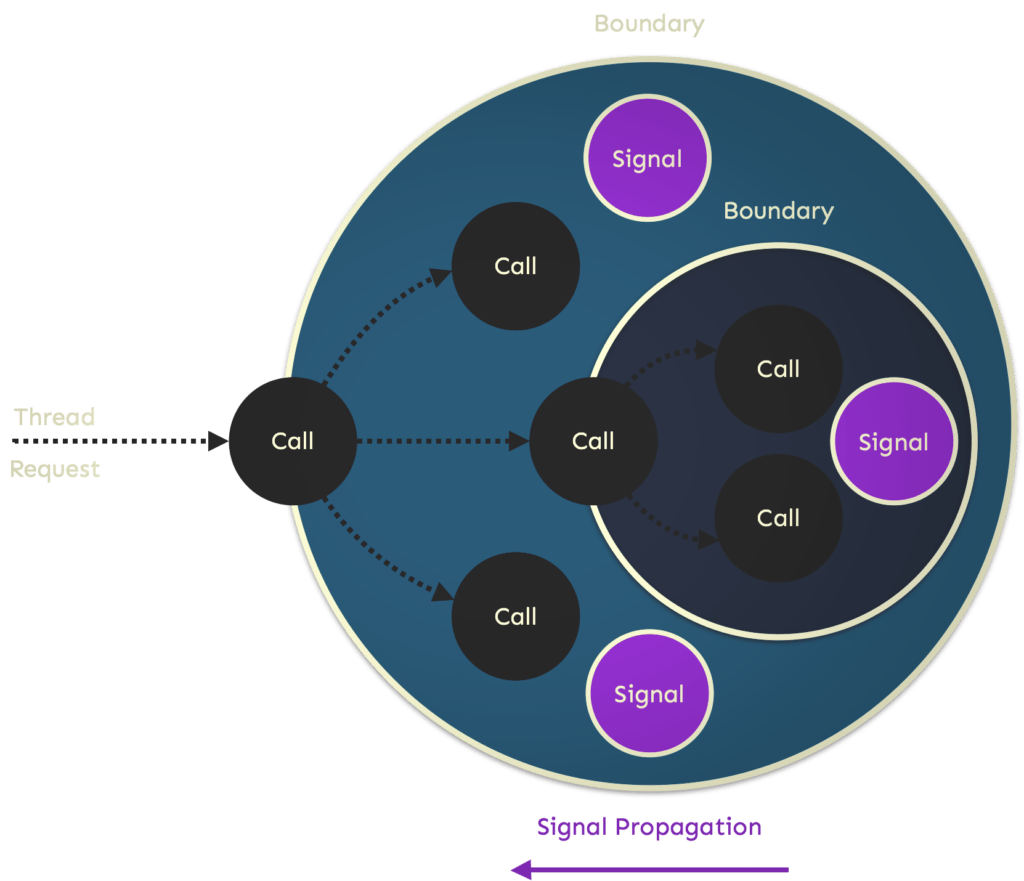
An emit shouldn’t result in any object being created or control being passed elsewhere in the software. It simply updates the numeric values behind each property as variables local to the function. Here, the variables are local to the boundary, which encloses one or more callers and callees. When execution exits the scope of the boundary, rules are applied, which in turn can fire actions that propagate one or more signals to the enclosing boundary, if any.
New signals can also be composed from existing signals within the boundary and propagated upwards. Signals can be renamed, and their strengths transformed (dampened or amplified) before propagation. Even at the boundary, signals can be emitted within the current scope, leading to additional rules being evaluated and actions fired.
However, care must be taken to avoid unwanted recursive cycles. The underlying mechanism is adaptive, filtering out signal noise at the earliest possible opportunity in the evaluation and cutting short signal propagation upwards through enclosing boundaries.
Signal Boundaries
Boundaries make signals so powerful as they net (capture) and retain the signaling across multiple enclosed call interactions. They bring a distinct hierarchy, low to high in terms of abstraction, to signal processing and propagation, much like the memory structure that underlies cortical learning algorithms.
Each signal boundary can observe and store the signals propagated up to it by the boundaries it encloses. Still, it can only see the signals in its boundary enclosure (parent) that it’s propagated and only the cumulative totals and counts for those propagations. This is incredibly important because it reduces the possibilities of signal interference across different call paths with different behavioral characteristics.
Boundaries allow enclosed method calls to maintain a conversational state in the scope of a direct or indirect caller method through a signal’s count and total cumulative values. The count and total for a signal will differ within each enclosing‚ boundary until the outermost boundary scope has exited and all propagations have occurred.
A helpful way of thinking about boundaries is as conversation threads, as in the typical online forum definition, nested within another conversation thread, which can be nested in another conversation thread. You can see the conversations from your conversation, but you can’t see the conversations from the same conversation thread you were forked from. Each conversation thread maintains the memory of its nested conversations, but each signal history is isolated. It’s the responsibility of the forking conversation to memorize the essence of each conversation forked from it and to reconstruct its history every time the same conversation starts. This is automatically handled by the signals’ runtime without any work on the developer’s part other than specifying suitable boundaries and then, most importantly, creating such boundaries with names that distinctively classify (or delimit) them. Boundaries demarcate the scope of a conversation – a kind of transaction for signals.
There are two signal boundary types: anonymous and named. A developer can use an anonymous boundary to restrict the propagation of signals emitted within a method and the methods (directly or indirectly) it calls. It can also hide implementation details or net all signals and translate them into something more meaningful to callers, similar to a try-catch-throw pattern. It also limits the duration of the boundaries below it.
A named boundary has many advantages over an anonymous boundary. Firstly, the signaling system can use the name of boundaries and the unique paths it creates to regionalize the memory it uses to reduce signal noise adaptively. Secondly, complex event processing (CEP), like signaling rules, can be externalized in configuration and keyed on such names and paths. Thirdly, it adds high-level workflow insight. Fourthly, it allows for adaptation via the automatic downward propagation of signal signatures. Finally, boundaries can be named based on context rather than the code.
Boundaries can serve as a point in the execution to apply adaptive control and quality of service (QoS) before a boundary is entered and after it is exited, with both persisted and present signal sets influencing such intervention.
Signal Rules
Signals allow for rules to be fired and listeners to be notified at each stage in the life cycle of a named boundary. Rules will conditionally match the occurrence, strength, and sequencing of signals emitted within the scope of a boundary, including that of nested boundaries. Such rules are defined externally in configuration and keyed on boundary namespaces. A matching rule can restrict the propagation of one or more signals. It can also create and emit a new higher-level signal within the scope of the boundary and/or its enclosing boundary. The signal runtime will automatically maintain this traceability. Listeners, externally configured like rules, can also be attached to a named boundary for more elaborate rule matching and integration with other measurement and monitoring solutions and systems.
Software Adaptation
Most library developers would readily accept the need for greater instrumentation via something like signals, though it is expected it’d still be given a back seat to functional requirements, and there would be a reluctance to change existing implementations. To alter that viewpoint, greater value must be obtained from the signals emitted. Such value can be obtained through the dynamic runtime adaptation of the library based on its signals.
Signals can be used with adaptive control valves to improve the search for a library component’s optimal and sustainable workload. Signals can be emitted privately within the library and then reflected upon at the ingress points into the library to drive its internal self-regulation mechanisms in a far more natural and comprehensive manner than is typically done in code today. Signals can be interpreted by callers and used to alter future creation and usage of a particular data structure and algorithm.
Far more important is that signals emitted beyond the library boundaries and passed up the caller-to-callee chain can be sent back down after signal noise reduction, then used to alter the execution flow within the library, with such behavioral change reflecting more of the caller context than the generality of the library.
A problem for dynamic runtime adaptation is that the class can’t accurately predict usage patterns or capacity needs within the current execution context because it can’t determine the most appropriate caller or caller-to-callee sequence on which to base such predictions. It simply can’t see or identify who’s interacting with it. There is no readily available means for recollecting or reconstructing conversations other than what is maintained in its internal state. Here, signals can help be the digest, a profile signature, of such interactions, collected by one or more callers, then made available at the boundary of subsequent interactions.
A boundary created by a caller that plans to make multiple calls into a library within the current execution context can also serve as a means to store memory signals and eventually signal sequencing across the multiple enclosed interactions – for both stateless and stateful components.
Signal sets in the context of adaptation act as classifiers of the caller(s) and context. Signal sets are derived, profiled, and refined automatically by the underlying signaling engine throughout multiple boundary path transverses. Some signals within such profiled sets will serve as operational hints or directives in servicing future interactions. Other signals will be used to identify or mark a caller uniquely. The beauty of this is that the direct or indirect caller needn’t know how marking is done and which signals drive adaptation (or control).
The meaning of signals is irrelevant to the caller. The only responsibility of boundary callers is that the signals be aggregated and persisted across deconstructions of boundaries and then materialized on reconstruction. Think of it as an incredibly powerful and flexible feedback and learning loop for software.
Signals also address a thorny issue in the design of feedback loops – how should control be exposed?
In traditional control systems, this is typically done via one or more set points that regulate flows and processes within a plant. A sensor is continuously measured, and a controller interprets measurements and then translates them into actions interacting with the controlled process (plant). With signals, the operational knowledge doesn’t necessarily need to be spread across system components. The process (plant) can generate the signals that drive its subsequent execution behavior, with the boundary serving as the context and memory for such adaptations and regulations. When a new boundary is created, the process can start the “observe, learn, and adapt” cycle all over again but be tailored to this new context.
Signal Driven Development
Signals can be extremely useful for application and library developers, allowing them to collect much more relevant data at runtime needed to guide the development of coding heuristics – optimizing for the common case.
Such measurement and collection enable offline and online software adaptation and fine-tuning of initial set points and thresholds in control mechanisms. It reduces a lot of guesswork for the developer when forced to commit to specifying default parameter values in constructing data structures (thread pools, etc.), though poor judgment can still be compensated by online adaptive techniques with some initial cost during the learning phase.
Signals are a modern form of usage tracking that goes far beyond recording what is called at the surface of an API. Signals can create a powerful design, development, and deployment feedback loop.