This article was first published in 2019.
Agents vs Agentless
Now and then, an observability or monitoring article will be posted, pitting agent and agentless-based architectures against each other. This is unfortunate as it often results in many not seeing the real underlying difference, which is less about installing local agent software and more about the efficient and effective communication of contextual state – normalized or not. We should not differentiate whether an agent is deployed, especially with companies electing to manually instrument some parts of an application’s codebase using open-source observability libraries.
Instead, we should consider whether the observer, an agent or library, is stateless concerning what and how it observes, measures, composes, collects, and transmits observations.
Stateless vs Stateful
With a stateless observer (and backend), each time an event occurs and calls into the instrumentation library, the entire contextual hierarchy must be transmitted to a backend – invariably, a big data sink in the cloud. The event payload for a stateless observer needs to repeatedly send many (identity state) tags about the enclosing context hierarchy, such as cluster, host, container, pod, process, and thread – flattened and bloated.
On the other hand, a stateful observer will send multiple different types of payload to the backend when it discovers objects of interest (contexts) and determines a state change. There is a conversational dialog with the backend in building a normalized representation of the reality the observer exists within and readily perceives.
Contexts are mirrored in the backend, with transmissions only including what is needed to maintain this. Event payloads need only an identifier for the immediate enclosing context – efficient and effective.
Flat Fat Events
Wide events are another way a vendor can describe an unnormalized semi-structured data collection transmission encoding in many cases. This can be attractive for a vendor but less so for their customers, as there is no need for heavy up-front engineering work in contextual model design. Vendors need only allow an observer to send as many arbitrary tags (or labels) as possible every time an event is transmitted. The costly engineering effort falls on the users of the instrumentation library and those tasked with trying to piece everything back together again through custom dashboards and multitagged multi-dimensional rows and tables.
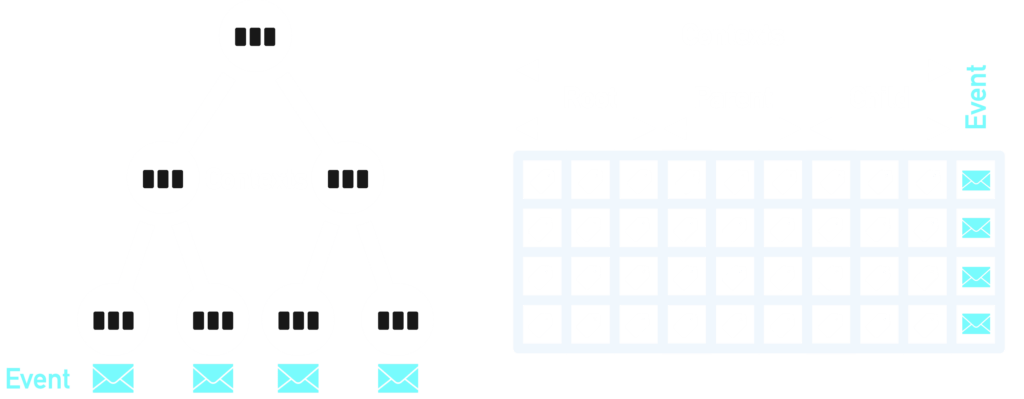
Customers of denormalized data backends nearly always end up spending a significant amount of time attempting to define a company standard set of tags or labels before even getting to the most challenging and impractical task – linking dashboards together by way of multiple tag sets embedded in pages, widgets, and URL references.
Contextual Navigation
A proper context-based observability model, with normalized forms, makes navigating infrastructure and service maps nearly effortless – up and down layered stacks and across system and service boundaries. With a good UX/UI design, moving between multiple contexts, both spatially and temporally based, can be highly productive in reducing the cognitive load on operations staff. When offered mostly a denormalized and heavily tagged data backend, engineering teams will become entangled and lost in the data fog, losing sight of bounded contexts. Once such forms are lost to the human eye, the recognition of significant change will follow suit.