The Percept
With the latest update to the Substrates API, I have begun the metamorphosis from being a foundational framework for instruments within the context of observability to a general-purpose event-driven data flow library interface supporting the capture, collection, communication, conversion, and compression of perceptual data through a network of circuits and conduits. For the most part, Percept, a new concept, replaces Instrument throughout the interface, with Instrument now being a subclass of Percept, as is the new interface Sensor.
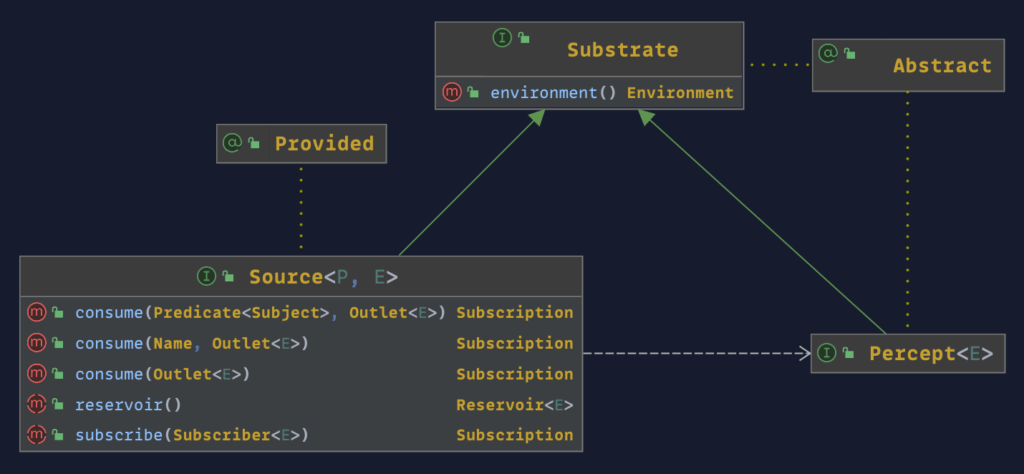
The Instrument interface should be extended when methods are made available for direct and explicit generation of events, as in the case with the Publisher interface. The Sensor is for interfaces where external changes generate events; an example would be the Clock interface. Sensors like the Clock interface are seen as headless.
The remaining part of this post will describe how I got to this point in the design of the Substrates API.
Probes and Signals
In 2013, while designing the Signals API, it became clear that there were conceptual elements the API shared with the Probes API released in 2008, such as Context, Name, and Environment. I decided to copy the sources, improve on the existing interfaces, and revisit the unification at some point when usage information was available.
At this point, the Signals API was generic and focused on bringing self-adaptive capabilities to any software component that needed a means of self-profiling and learning. The model included such concepts as Signal, Strength, and Boundary, along with Context, Environment, and Name. Here, the Name represented a Sign.
But it was too generic for most newcomers. Most users could not imagine the self-awareness and self-adaptation capabilities they could imbue within their software and its source code. Autonomic Computing seemed alien.
Back to the drawing board.
Signify and Service Cognition
With the next attempt, the concepts of Signals were mapped to a new term I coined – Service Cognition. The new design would offer out-of-the-box support for two sign sets specific to the service-to-service interaction domain. The first set, categorized as a Signal, would provide 16 signs that listed the primary operations and outcomes of an interaction with a service such as CALL, FAIL, SUCCEED, RETRY, DROP, etc. The second set was a small list of Status signs inferred from a Signal sequence, such as STABLE, DEVIATING, DEGRADED, etc.
I had narrowed the scope of Signals, removing the self-adaptive capabilities. Still, it resonated with vendors so much that Instana undertook to integrate the approach into their product portfolio.
Most experienced engineers in the application performance monitoring space had long recognized that distributed tracing was not delivering value or sustainable in the long run. Still, the market and the community were proving resistant to change in moving beyond a 20-plus-year-old technology. From a technical perspective, the Signify approach made perfect sense. For product management and marketing, it meant (re-)educating the market, which was extremely difficult when a distributed tracing standard was in the works that offered more to vendors than customers. No company was big enough to stand up and lead the way; the masses of mediocrity had spoken.
Problematic Pipelining
Signify was a fantastic approach and superb technology, but the integration effort would prove more difficult than could be imagined. At that time, it was difficult to pinpoint the cause of resistance. People? Product? Pillars?
I learned that people can be pillars in being steadfast and closed-minded in considering change.
Pillars are just another name for pipelines; pipelines are silos that span end to end. Most application performance monitoring vendors, now known as observability vendors, initially built each new pillar as a separate communication pipeline from source to sink. There was little reuse, except maybe in the user interface and the back-frontend.
Setting up a new pipeline was not like today in modern data engineering. Everything seemed to start from scratch, and somehow, I had to figure out at what point all these pipelines would converge and who would be responsible for stitching everything together, as the theory goes in data fusion. It did not help that product management had incentivized product engineering to develop new distributed tracing instrumentation agent packs for whatever application framework library was out in the wild. There were hundreds of instrumentation packs, all incremental and relatively easy to develop and shout about in marketing bulletins but of little substance regarding innovation.
Then COVID happened; for most of us in the company, the rest was history after a few minutes on a Zoom call.
Event-Driven Architectures
I always felt that Signify, which I had at this point open-sourced under the new name of OpenSignals, could be used in a broader business context, far beyond just monitoring software services, so I jumped at the chance to bring this thinking to parcel logistics at PostNL in architecting a Control Tower – a digital twin of the physical network of roads, depots, trucks, vans, trolleys, sensors, beacons, parcels, sorting machines, and addressable places.
I would ensure that data pipelines would not be the problem this time. I did this by bringing on a new source or sink and connecting it all up seamlessly using metadata captured and pushed through a CI/CD pipeline. This new thing I termed a Habitat, seeing it as a digital ecosystem of forms (entities), functions (agents), and flows (pipelines). A new pipeline or augmentation of the Control Tower was just a Git commit and push away.
It looked and sounded great until you had to map it to Amazon AWS services, starting with something like EventBridge, a weirdly quirky interface that involved out of CloudWatch.
Even with great automation in the deployment pipeline, having data and events transmitted around loosely connected distributed services is a painful development experience, especially when the workflow is conceptually simple, the change small, and the resource needs are available locally. AWS and all its services needed to be pushed down below the surface; such interfaces offered no value beyond the operational capabilities and capacities. But AWS is good at creating cults of community champions who want everyone to suffer equally. Such abstractions aimed at supporting developers are considered subversive attempts at gaining cloud vendor independence.
You fix one bottleneck only to run into another, created and maintained by a far greater adversary.
The primary lesson I learned was to make it easy to onboard new instruments (publishers) and observers (consumers) and hide the distributed nature of event transmission and transformation as much as possible.
At this stage, many of the concepts within the original Signal design were now pulled down into the Substrates API as I tried to repackage up the foundational concepts of Habitat into a lightweight library, as opposed to a heavyweight and cumbersome distributed system of sources, sieves, and sinks. There were no event queues at this stage. Still, it was easy to design and develop new instruments on top of the Substrates API for rapid experimentation, which I sorely missed while working on the Control Tower project. No matter the instrument, building agents was a consistent experience of sourcing, subscribing, and sensing.
Event Sourcing
The Simz technology I had built in 2013 was a fully-fledged event sourcing and simulation solution, so when I got the opportunity to work on redesigning and refactoring an online job advertisement platform connecting job boards to advertisement outlets that relied heavily on Axon, I was curious to see how the theory, technology, and tooling had evolved over the last decade since I had created a “Matrix” for software machines and their memories.
I had gone from managing a network of agents transporting packets over a network to trucks moving parcels between depots, and now advertisers and publishers exchanging content and clicks—networks of networks.
It wasn’t very reassuring. Simz had been able to stream and replay in near-real-time up to 750 million events a second, with an event being, on average, only two bytes between sender and receiver. With Axon, everything seemed to be in a state of slow motion; at times, I could see events go through the pipeline in single digits. Rebuilding projections could take days when it would have taken Simz minutes. JSON was everywhere, and nearly all interaction was one or more remote calls. The concept of context and aggregate was so kludgy; most of the time, you wanted something between context (store) and aggregate (root) – a process, workflow, or circuit.
However, the most significant pain point was the number of workflow scheduling solutions co-existing within the same runtime process. Every new library, within what was effectively an event pipeline, such as service request processing, event streaming, fibers and effects, topics and queues, and so on, brought with them yet another interface for asynchronous execution. Crossing library boundaries and the underlying threading was fraught with danger and endless debugging sessions that never seemed to get close to what was likely happening in production.
The amount of logic devoted to actual business value generation was minuscule compared to all the encoding, transmission, and decoding code that had to be written. I came away thinking that much of the code the team had built over two years could have been done within 2-3 months if the data/event flow interface could be harmonized via a circuitry-inspired design. Since leaving the Ads space, this has been the focus with Substrates.
Next Steps
The big plan has not changed much since 2013 – to build out humane technologies to aid in developing Digital Twins, whether a mirror of the physical or virtual world, as in the case of Simz. On the immediate horizon is to determine whether the Substrates API, with its circuitry, can be a universal client interface for producers and consumers of data streamed, stored, serviced, and searched by MQTT, Kafka, and other distributed systems.