Context Computation
In a previous post, we introduced the concept of Service Cognition in the context of information exchange within a meeting of two parties (agents). It was shown that any information exchange between parties could be viewed as service interaction, with the parties alternating between service consumer or provider roles. This post explores it within a more relatable context: computation.
If we consider a typical web application, we can regard it as a service that delivers pages to a user’s browser. The user is a consumer. The microservice, exposed as an API, can be considered a provider of a service whose consumer is the web application.
In the diagram below, the Observer represents the AIOps component, commonly an agent or superagent (agent aggregate). The Dashboard component, typical of current enterprise environments, visualizes the data collected. The dashboard is depicted separately from the observer, as it primarily serves the need of application developers and site reliability engineers to see collected data, whether it has any significance or utility. The AIOps component does not necessarily communicate with the Dashboard, though sharing mental (state) models between human and machine operators is paramount for successful service operations.
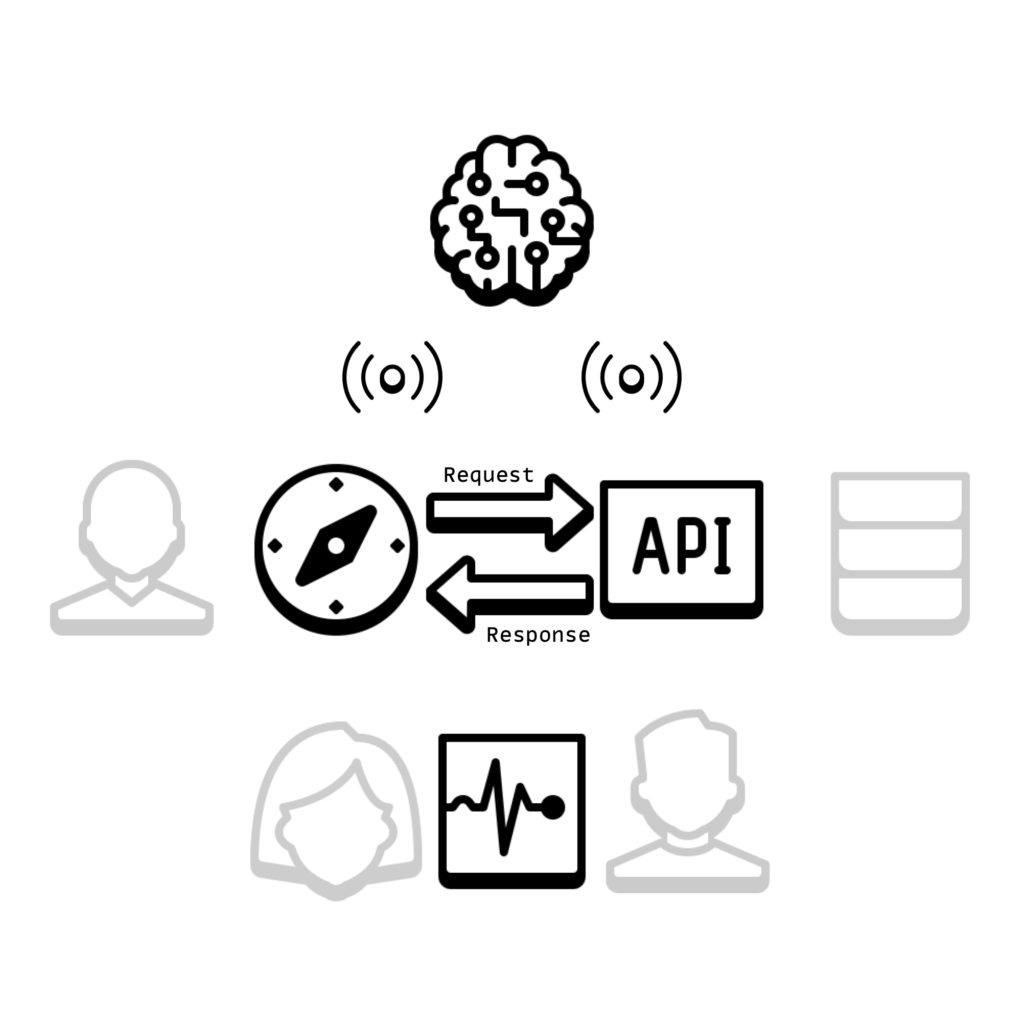
Situation Awareness
Two primary parties are involved in the service interaction – the web application and the microservice. But when assessing the current situation, many more cognitive agents and their perspectives can be included. The user of the web app is one. Those looking at the system through the lens of the Dashboard are another. Each can form a distinct opinion of the present situation and the potential (predicted) future scenarios. Even those looking through the same lens can interpret the data differently. It is this continuous assessment of stability, distributed across agents, that we refer to as service cognition.
The difference of opinion is problematic because the implication is that multiple realities exist and somehow need to be reconciled for decision-making to be effective. There can be valid reasons for assessment differences due to the point of experience and the measurement method, especially when we consider that a medium, such as a communication network, exists between consumers and providers as well as agents and observers. But one source of difference is unnecessary, and it is that the language is data.
Those looking at a dashboard are not directly processing what they see via a standard service language that includes an ontology (concept) and taxonomy (classification). Instead, what is seen are data points that need to be interpreted and transformed, which is further complicated by the fact that such points can be rendered differently – (spark)lines, (pie)charts, graphs, tables, etc.
A picture is worth a thousand words and comes with many more interpretations. The situation is lost in pixelated data translations!
Service Cognition
Today’s data, such as logs, traces, and metrics, are too far removed to be the basis for a language and model that illuminates the dynamic nature of service interaction and system stability inference and state prediction formed across distributed agents and reconciled in the form of collective intelligence that more closely compares with the AIOps that engineers need to more effectively and efficiently manage complexity and change as opposed to the one that merely translates natural language text into pixelated art.
In the next post, we will start with the very foundations of a service language and model by introducing a set of signals (tokens) that can describe nearly all service interaction events of significance and, when sequenced, supports effective status inference.
